

intro
data augmentation 이란 학습 시에 overfitting이 염려될 때, 좌우반전된 이미지나 노이즈가 추가된 이미지를 학습시켜 overfitting을 방지하는 기법입니다. 단순히 데이터를 불려서 overfitting을 방지하는 기법이라고 많이 알고 계실 텐데, 관련된 자료를 찾아보던 중 data augmentation을 적용할 때 고려해야 할 점이 몇 가지 있는 것을 알게 되었습니다. 이에 대해 제가 이해한 내용을 포스팅하도록 하겠습니다.
1. data augmentation을 하는 이유

만약 사람을 구분하는 딥러닝 모델이 있다면, 각도가 다른 두 개의 사진 모두 같은 사람으로 인식해야 합니다. 하지만 모든 각도에서 사람을 촬영할 수는 없기에, 모델을 잘 학습시키기 위해서 이러한 데이터를 직접 만들어야 합니다. 일반적으로 data augmentation을 하는 방법은 몇 가지 방법은 다음과 같습니다.
- 평행이동
- 회전
- 크기 변환
- 좌우반전/상하반전
- 기울이기
2. 두 가지 data augmentation구현 방법
저는 처음에 data augmentation이 단순히 변형된 이미지를 추가하면 된다고 생각했었는데, 알고 보니 제 생각과 조금 달랐습니다.
1) 데이터 셋 추가
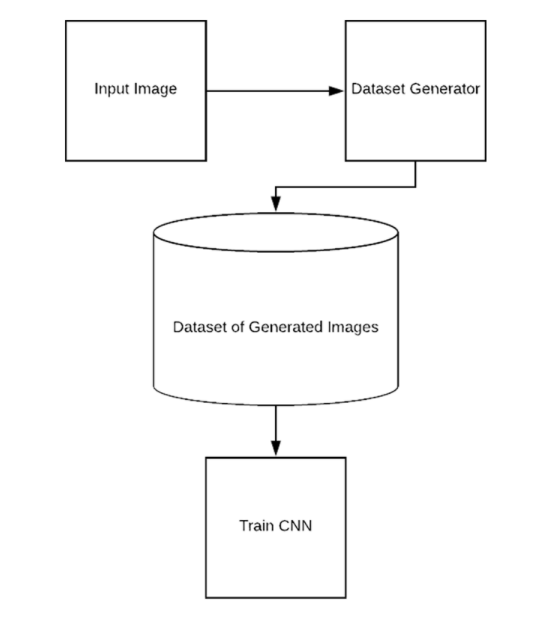
첫 번째 방법은 다음과 같습니다.
- Input 이미지를 로드한다.
- Dataset Generator에서 data augmentation 기법을 이용하여 학습 데이터 셋에 변형된 데이터를 추가한다.
- 추가된 이미지와 원본 이미지를 함께 학습시킨다.
아마 가장 일반적으로 생각하는 방법일 텐데요, 이 방법에는 문제점이 있습니다.
- 추가할 수 있는 변형된 데이터의 개수가 정해져 있습니다.
- 모델은 데이터를 통해서 학습하게 되고, 결국 추가한 변형된 데이터에 대해 다시 overfitting되는 결과를 낳게 됩니다.
- 즉, data augmentation을 통해 얻고자 했던 효과가 미미해집니다.
2) 학습 시에 실시간으로 데이터를 변형하는 방법
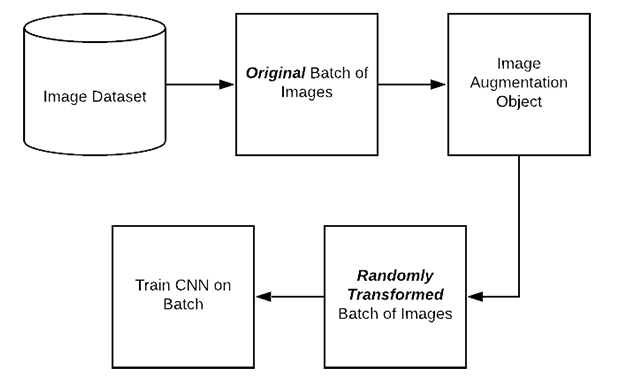
과정을 설명하자면 다음과 같습니다.
- 원본 이미지 데이터를 로드한다.
- 이미지 augmentation 객체에 원본 이미지를 등록한다.
- 학습할 때, 각 batch에 원본 이미지를 data augmetation을 적용시켜 변형한 이미지를학습시킨다.
- 모든 batch 마다 3의 과정을 반복한다.
위 과정이 1)에서 서술한 방법과 다른 점은 다음과 같습니다.
- 미리 저장된 데이터 셋을 이용하지 않습니다. 대신, 학습 시 각 배치마다 원본 이미지로부터 다르게 변형된 데이터들을 학습합니다.
- 그렇기 때문에, 모델은 매 에포크마다 다른 데이터를 학습하게 됩니다.
- 결과적으로, overfitting을 방지할 확률이 조금 더 높아집니다.
이런 방법을 이용하게 되면 원본 이미지는 전혀 학습하지 않고, data augmenation에 의해 변형된 이미지만 학습하게 됩니다. 그렇기 때문에, 이러한 방법을 이용하면 여러 방법으로 변형된 이미지를 모델이 학습할 수 있게 되면서, 모델이 조금 더 일반화되고, overfitting이 줄어듭니다.
3. Keras ImageDataGenerator 예제 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
y_train = np_utils.to_categorical(y_train, num_classes)
y_test = np_utils.to_categorical(y_test, num_classes)
datagen = ImageDataGenerator(
featurewise_center=True,
featurewise_std_normalization=True,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True)
# here's a more "manual" example
for e in range(epochs):
print('Epoch', e)
batches = 0
for x_batch, y_batch in datagen.flow(x_train, y_train, batch_size=32):
model.fit(x_batch, y_batch)
batches += 1
if batches >= len(x_train) / 32:
# we need to break the loop by hand because
# the generator loops indefinitely
break
keras 공식 예제 코드를 보며 2)와 같은 방법이 어떻게 적용되었는지 확인하도록 하겠습니다.
예제는 cifar-10 데이터를 분류해내는 모델을 학습시키는 코드입니다.
1
2
3
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
y_train = np_utils.to_categorical(y_train, num_classes)
y_test = np_utils.to_categorical(y_test, num_classes)
먼저, train data와 test data로 나뉜 데이터를 로드합니다.
1
2
3
4
5
6
7
datagen = ImageDataGenerator(
featurewise_center=True,
featurewise_std_normalization=True,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True)
그다음 부분에, ImageDataGenerator 함수를 호출하는데요, 여기서 어떤 방법을 적용하여 변형된 이미지를 만들어 낼 건지를 옵션으로 넘겨줍니다.
1
2
3
4
5
6
7
8
9
10
11
# here's a more "manual" example
for e in range(epochs):
print('Epoch', e)
batches = 0
for x_batch, y_batch in datagen.flow(x_train, y_train, batch_size=32):
model.fit(x_batch, y_batch)
batches += 1
if batches >= len(x_train) / 32:
# we need to break the loop by hand because
# the generator loops indefinitely
break
그리고, 학습을 시키게 됩니다. 여기서 보시면 for문에서 매 배치마다 datagen.flow를 호출해 매번 다른 데이터 셋을 받아오게 되는 것을 알 수 있습니다.
결론
위에서 제시한 것 처럼 프레임워크에서 대부분 data generator를 구현한 함수를 제공하지만, 상황에 따라서는 image data generator 함수를 직접 구현해야 하는 경우도 있습니다. 여러분들도 직접 augmentation 코드를 구현해야 할 때, 이런 점을 고려해서 더 좋은 방법으로 구현하셨으면 좋겠습니다.