

Flask를 통해 구축한 서버에서, RestAPI를 사용해 DenseNet121모델을 통해 사진을 분류하고 그 결과를 보여주기까지 학습하였다.
팀에서는 프로젝트를 위 구조를 이용해서, 개의 사진을 올리면 품종을 알려주고 그에 대한 정보를 주도록 진행하고자 하였다.

일단 추가학습을 시키는 모델은 팀원에게 맡기고.. 이번에는 결과페이지의 구성을 알차게 하려고 한다.
위키 API 사용하기
우선 분류한 클래스의 결과를 위키피디아에 검색하려고 한다.
찾아보니 위키피디아 API가 존재하였다.

우선 위키피디아 api를 다운받는다.
1
pip install wikipedia -api
내가 숙지한 사용법은 다음과 같다.
위키피디아의 언어를 설정하고, 내가 원하는 페이지를 찾아 데이터를 얻어오는 방식으로 사용하였다.
1
2
3
4
5
6
7
8
9
10
#위키api
import wikipediaapi
#class_name = 분류한 개 이름
def wiki(class_name):
wiki = wikipediaapi.Wikipedia(language='en')
p_wiki = wiki.page(class_name)
#페이지 있으면 페이지 출력
if(p_wiki.exists()):
print(p_wiki.text)
골든 리트리버 사진을 넣었더니 golden_retriever로 분류되고, 위키 페이지에서 전체 내용을 잘 가져온다.
구글 번역 API 사용하기
그럼 한국어로 검색하면 어떨까
우선 이름을 한국어로 바꿔서 검색하기 위해 구글 번역 API를 사용하고자 한다.
아래는 무료로 제공하는 번역 api이고 유료버전인 Google Cloud Translation도 존재한다.

무료로 제공되었던 번역 api (googletrans)가 에러가 많고, 작동이 안된다는 게시글이 많아서 기존의 install 링크가 아닌, 아래 링크에서 다운받아서 사용하였다.
1
pip install git+https://github.com/alainrouillon/py-googletrans@feature/enhance-use-of-direct-api
간단한 사용법은 translate 함수를 사용해서 사용하면 된다.
src는 원래 언어 (생략가능) -> dest는 바뀌는 언어
1
2
3
4
5
6
from googletrans import Translator
trans = Translator(service_urls=['translate.googleapis.com'])
result = trans.translate(class_name, dest='ko', src='en')
#origin = 원래 -> text = 변환
print(result.origin +" " + result.text)
위 코드를 추가하고, 위키는 한국으로 바꿔서 돌려보았다.

한국 위키에서도 잘 가져온다. 함수는 아래와 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#english word -> translate korean -> search wiki
def wiki2(class_name):
wiki = wikipediaapi.Wikipedia(
language='ko',
extract_format=wikipediaapi.ExtractFormat.WIKI)
trans = Translator(service_urls=['translate.googleapis.com'])
result = trans.translate(class_name, dest='ko', src='en')
class_name = result.text
print(result.origin + " " + result.text)
p_wiki = wiki.page(class_name)
if(p_wiki.exists()):
print(p_wiki.text)
하지만 실제로 이렇게 사용했을때 원했던 결과와는 다른 문제점이 발생하였다.
1- 모델에서 뱉어내는 개 이름이 정확한 품종의 풀네임이 아닌 경우가 있어서, 위키에서 검색을 잘 못한다.
ex) 웰시코기의 경우 풀네임이 Pembroke Welsh Corgi -> Pembroke로는 검색이 안됨.
2- 그리고 위키API에서 없는 페이지의 경우, 특정 페이지가 아닌 링크가 담긴 검색결과가 나온다.
따라서 당장은 특정 사이트에서 크롤링하는 방법을 사용해보기로 생각했다.
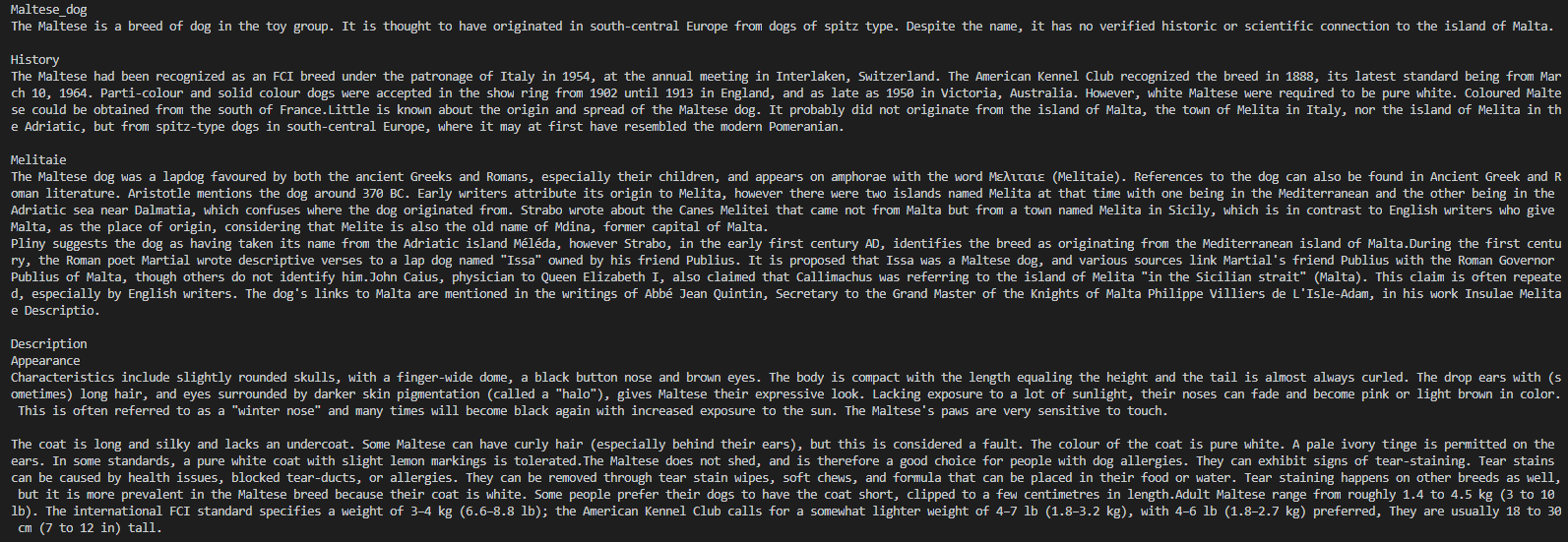
기존 사이트의 URL을 통해 크롤링을 하려고 하면, 추가 라이브러리를 사용하면 된다.
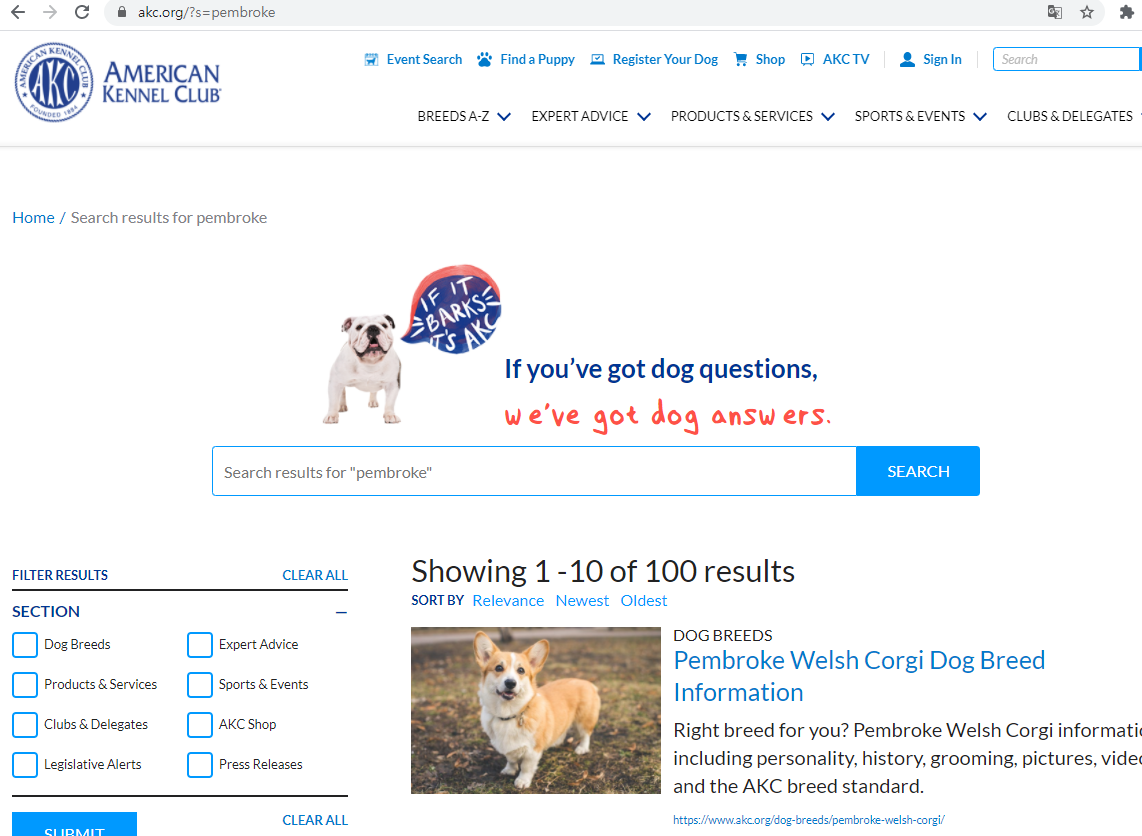
우선 타겟으로 한 사이트는 다음과 같다. 미국 애견 협회로 세계에서 2번째로 오래되었다고 한다.
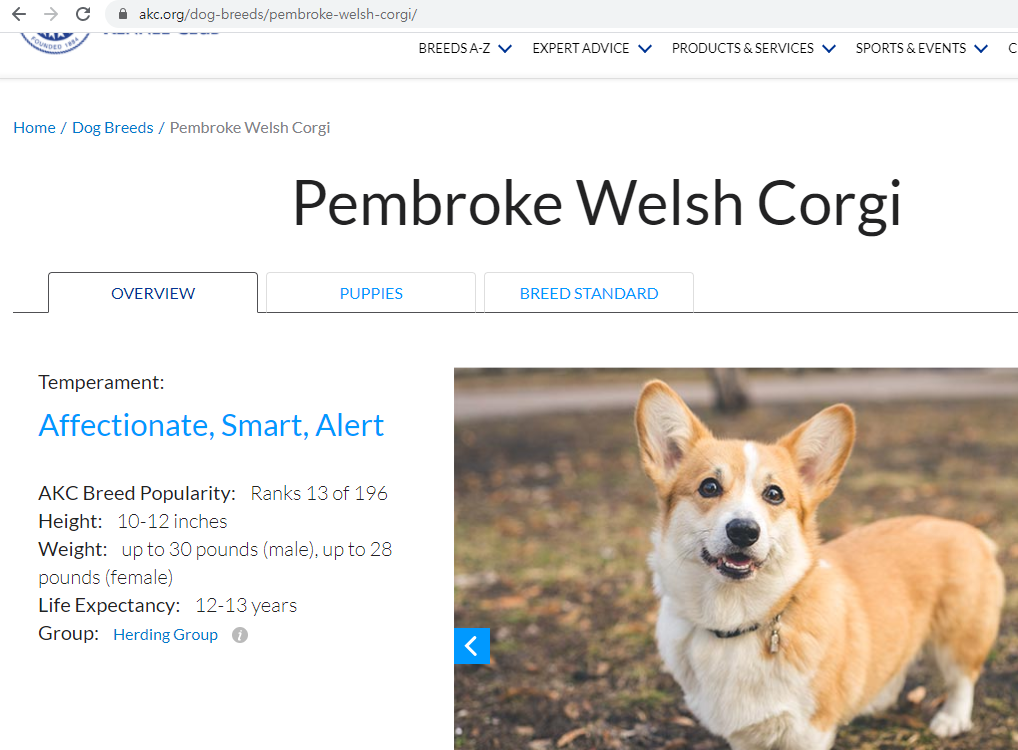
그리고 1번의 문제를 해결하기 위해, 위 사이트에서 검색한 결과에서
제일 상단에 위치한 저 Breed Information (종 정보) 링크를 통해 정보를 얻어내고자 한다.
BeautifulSoup을 사용한 크롤링
파이썬으로 크롤링을 할때 가볍게 사용하는 라이브러리로 Selenium과 Beautiful Soup가 있는데, 더 간편한 느낌의 Beautiful soup를 사용하도록 하겠다.

1
pip install requests beautifulsoup4
간단한 사용법은 다음과 같다. 생성되는 저 BeautifulSoup 객체를 조작하여 크롤링을 하면 된다.
1
2
3
4
5
6
7
8
from bs4 import BeautifulSoup
#파일 열어서 넘기기
with open("htmlfile.html") as fp:
ss = BeautifulSoup(fp)
#html 내의 내용을 문자열로 넘기기
ss = BeautifulSoup("<html>abcabacabc</html>")
URL을 통해 객체를 생성하는 방법은 다음과 같다.
1
2
3
4
5
from urllib.request import urlopen
#타겟 사이트
html = urlopen("https://www.akc.org/?s=" + class_name)
bsObject = BeautifulSoup(html,"html.parser")
자 그렇다면, BeautifulSoup 객체를 어떻게 조작해야 할까.
타겟 사이트에서 어느 부분이 html 문서에서 어떤 역할을 하는지 먼저 파악해야 한다.
가장 간편한 방법은 크롬 개발자모드를 사용하는 방법이다.
크롬으로 사이트 접속 -> f12 (개발자모드) -> Elements -> ctrl+shift+c 누르기 -> 궁금한 부분 클릭
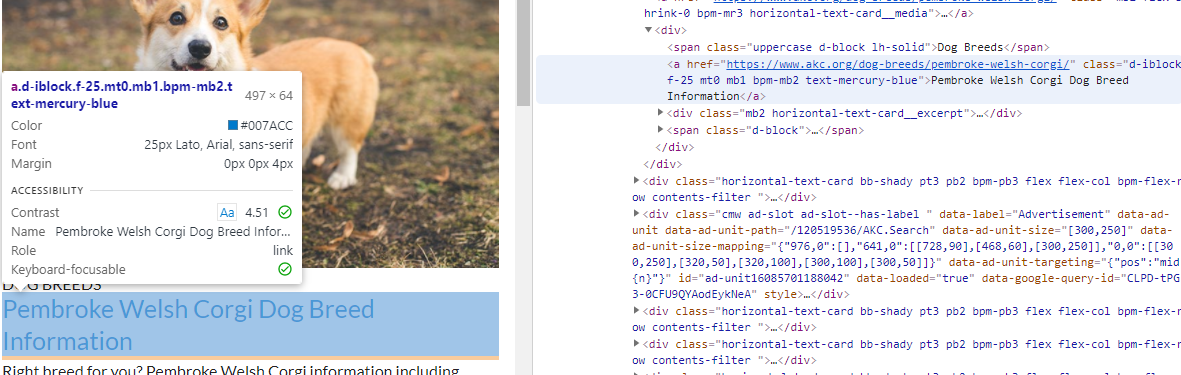
a 태그안에 들어있는 저 주소를 가져오는 것이 1차 목표이므로,
HTML의 내부 태그에 따라 여러 메소드가 존재하지만, 나는 find_all 메소드를 사용하여 원하는 정보를 얻어내고자 한다.
1
2
3
4
5
6
7
8
#get secondUrl
for link in bsObject.find_all('a'):
url = link.get('href')
if url is not None:
if("/dog-breeds/" in url) and not(url.endswith("/dog-breeds/")):
secondUrl = url #secondUrl로 저장
print(link.text.strip(), url)
break
a태그 내용을 다 긁어오고 -> 그중 href를 추출해서 -> 원하는 정보에 맞는 타겟만 뽑아내면 된다.

그럼 이제 다시 이 링크를 통해 들어가서 정보를 뽑아내려한다.
find 메소드를 다음과 같이 사용하면 태그와 특정 클래스를 특정하여 얻어낼 수 있다.
1
name = bsObject.find("h1",{"class" : "page-header__title"}).string
함께 제공하는 사진 역시, db에서 가져오는 링크형식이어서 무자비하게 링크를 긁어왔다.
최종적인 메소드는 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
#search from site
def dogSite(class_name):
html = urlopen("https://www.akc.org/?s=" + class_name)
bsObject = BeautifulSoup(html,"html.parser")
secondUrl = None
result = []
img_src = []
count = 0
#get secondURL
for link in bsObject.find_all('a'):
url = link.get('href')
if url is not None:
if("/dog-breeds/" in url) and not(url.endswith("/dog-breeds/")):
secondUrl = url
print(link.text.strip(), url)
break
#search at secondURL
if secondUrl is None:
information = "Sorry, We can't find an information"
name = class_name
result = None
img_src = None
else:
html = urlopen(secondUrl)
bsObject = BeautifulSoup(html,"html.parser")
#종 이름
name = bsObject.find("h1",{"class" : "page-header__title"}).string
name = name.replace("\n","").strip()
#정보 (요약)
for contents in bsObject.find_all("span",{"class":"attribute-list__text"}):
result.append(contents.string)
#설명
information = bsObject.find("div",{"class" : "breed-hero__footer"}).string
information = information.replace("\n","").strip()
#사진
for img in bsObject.find_all("img",{"class" : "media-wrap__image lozad"}):
img_src.append(img.get('data-src'))
count = count+1
#사진 5장 제한
if(count == 6):
break
return name, result, information, img_src
