
Distilling the Knowledge in a Neural Network
이승현
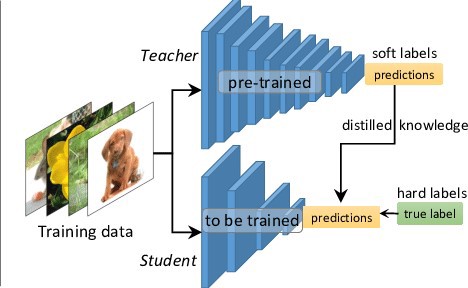
Knowledge Distillation(지식전이)는 미리 잘 학습된 큰 네트워크의 지식을 실제로 사용하고자 하는 작은 네트워크에게 전달합니다.
미리 학습이 잘 된 큰 네트워크와 경령화시키고자 하는 작은 네트워크 분류 결과차이를 최소화하도록 학습합니다.
- Background
- Neural Net Distillation
- Result
- Code Tutorial
Background
- 오버피팅을 피하기 위해서 Neural Net 에서 앙상블 기법을 사용하게 됩니다.
- 앙상블은 학습 및 추런에 계산시간이 많이 걸린다는 단점이 있습니다.
- 앙상블만큼의 성능과 적은 파라미터 수를 가진 뉴럴넷 모델이 필요합니다.
Neural Net Distillation
Neural Net은 Class의 확률을 Softmax Layer을 Output으로 이용해서 예측합니다.
수식은 아래와 같은데 q는 클래스에 속할 확률, z는 전 layer의 weight sum, T는 temperature라는 값으로 default 1로 둡니다.
T가 1이면 클래스에 속할 확률은 0 또는 1의 이진화된 결과값을 얻는데 이는 확률분포를 알기 어렵게 만듭니다.
Neural Net의 Output이 [0 0 0 1] 인 경우와 [0.1 0 0 0.9]인 경우가 있을 때,
[0.1 0 0 0.9]에서 0번 클래스가 0.1 인 것을 아는 것이 [0 0 0 1]의 Output으로 학습할 때보다 학습에 도움이 되는 지식을 가집니다.
개와 고양이가 같은 특징을 가지는 경우를 예를 들 수 있습니다.
T가 클수록 더 연속적인 확률값을 얻으므로 soft한 확률 분포가 클래스마다 만들어지게 됩니다.
soft하면 결과값이 천천히 증가한다는 뜻입니다. 하지만 T가 너무 커지면 모든 클래스의 확률이 비슷해집니다.
 (T가 무한히 커지면 exp은 1에 가까워집니다.)
(T가 무한히 커지면 exp은 1에 가까워집니다.)
Matching logits is a special case of distillation
만약 T가 무한히 커지면 Loss function에는 어떤 일이 생길까요?
크로스엔트로피C를 logit에 대하여 미분하면 아래 식으로 정리가 됩니다. v는 soft target 확률을 생성하는 weight sum값입니다.

T가 logit, z에 비하여 커지면 아래와 같이 Approximate할 수 있습니다.

만약 전 layer의 output값인 z, v zero-centered하다면z/T는 0이 됩니다.

여기서 알 수 있는 것은 T가 클 때는 Gradient가 작아지므로 좀 더 천천히 soft하게 학습하고, T가 작을 때는 Gradient가 커져서 좀 더 급격하게 학습합니다.
Result
MNIST
- Two hidden layer + Relu : 146 test errors
- Two hidden layer + DropOut : 67 test errors
- Two hidden layer + Relu + soft target : 74 test errors
Soft Target을 사용할 때 error가 가장 작습니다.
또한 놀라운 점은 숫자 3에 해당하는 데이터를 보여주지 않고 학습을 하였을 때 109 test error를 보여주었습니다.
학습하는 모델이 학습 중에 3을 본적이 없지만 soft label을 통해 3과 비슷한 숫자들을 통해 유추합니다.
Code
저는 Cifar10 Dataset, Tensorflow로 실험을 진행하였습니다. Code
Performance
Temperature : 10 온도에 따른 실험을 하진 못했습니다.
Small Network 과 Distillation의 성능이 비슷해보이지만, 학습의 안정성은 확실히 Distillation이 높았습니다.
추가 실험이 필요해보입니다.
|Model | Accurarcy | | —— | —— | | Small Network | 85%| | Big Network | 90% | | Distillation | 85%|
Parameter
|Model | Parameter| | —— | —— | | Small Network | 770,378| | Big Network | 3844938| | Distillation | 770,378|