
들어가며
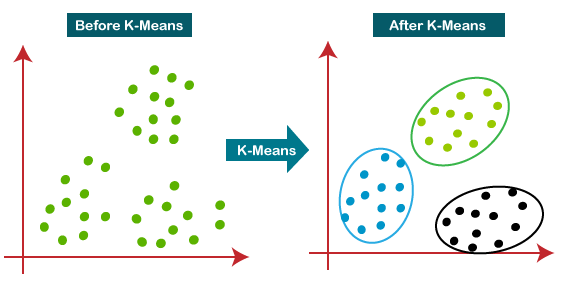
비지도 학습에 관심이 많은 만큼 이번 포스팅에서는 K-means 클러스터링에 대해 다뤄보겠습니다. 클러스터링은 분류 기준이 없는 상황에서 유사한 것들을 묶어주는 것인데 그중에서 K-means 는 주어진 K 값에 따라 K 개로 그룹 지어주는 알고리즘입니다.
과정은 대략 이와 같습니다 원하는 클러스터의 수(K)를 결정합니다. 무작위로 클러스터의 수와 같은 K 개의 중심점을 선정하고 이들이 각 클러스터의 대표가 됩니다. 나머지 점들과 모든 중심점 간의 유클리드 거리를 계산한 후, 가장 가까운 거리를 가지는 중심점의 클러스터에 속하도록 합니다. 각 K 개의 클러스터의 중심점을 해당 클러스터의 평균값을 통해 다시 결정합니다. 다시 결정된 평균값과 각각의 점들의 유클리드 거리를 다시 계산하고 재 그룹화합니다. 위 과정을 사용자의 설정 횟수에 맞게 반복합니다.
우선 필요한 모듈을 불러오고 무작위로 1000개의 점을 생성해 보겠습니다
1
2
3
4
5
6
%matplotlib inline
from sklearn.datasets import make_blobs
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import random
중심점이 5개인 1000개의 점 데이터를 무작위로 생성합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
points, labels = make_blobs(n_samples=1000, centers=5, n_features=2)
print(points.shape, points[:10]) # 무작위로 생성된 점의 좌표 10개 출력
print(labels.shape, labels[:10]) # 10개의 점들이 각각 대응하는 중심점(label) 값 출력
# 생성 데이터를 시각화 해보겠습니다. 이를 통해 생성된 데이터가 5개로 군집화 되어있음을 시각 데이터를 통해 확인 가능합니다
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1) # 축
# pandas DataFrame 형태로 변환하기
points_df = pd.DataFrame(points, columns=['X', 'Y'])
display(points_df.head())
ax.scatter(points[:, 0], points[:, 1], c='black', label='random generated data')
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.legend()
ax.grid()
# 클러스터 클래스에서 k-means 메소드를 불러오고 사용해보겠습니다
from sklearn.cluster import KMeans
kmeans_cluster = KMeans(n_clusters=5)
kmeans_cluster.fit(points)
print(type(kmeans_cluster.labels_))
print(np.shape(kmeans_cluster.labels_))
print(np.unique(kmeans_cluster.labels_))
# 이를 시각화해봅시다
color_dict = {0: 'red', 1: 'blue', 2:'green', 3:'brown', 4:'indigo'}
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
for cluster in range(5):
cluster_sub_points = points[kmeans_cluster.labels_ == cluster]
ax.scatter(cluster_sub_points[:, 0], cluster_sub_points[:, 1], c=color_dict[cluster], label='cluster_{}'.format(cluster))
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.legend()
ax.grid()
마무리
처음에 시각화했던 것과 동일하게 나왔으므로, 군집 화가 잘 되었음을 알 수 있습니다. 다음에는 DBSCAN 을 사용해 군집화를 해 보도록 하겠습니다. 감사합니다.