
RNN (Recurrent Neural Network)
RNN은 연속적인 데이터셋을 처리하기 위해 등장하였다.
예를 들어 문장의 경우 연속적인 단어로 이루어져 있고, 이를 처리하기 위해 RNN과 같은 시퀀스 모델이 등장하게 되었다.
가장 기본적인 RNN의 특징은 이전 계산 값을 다시 다음번의 학습에 사용하는 것이다.
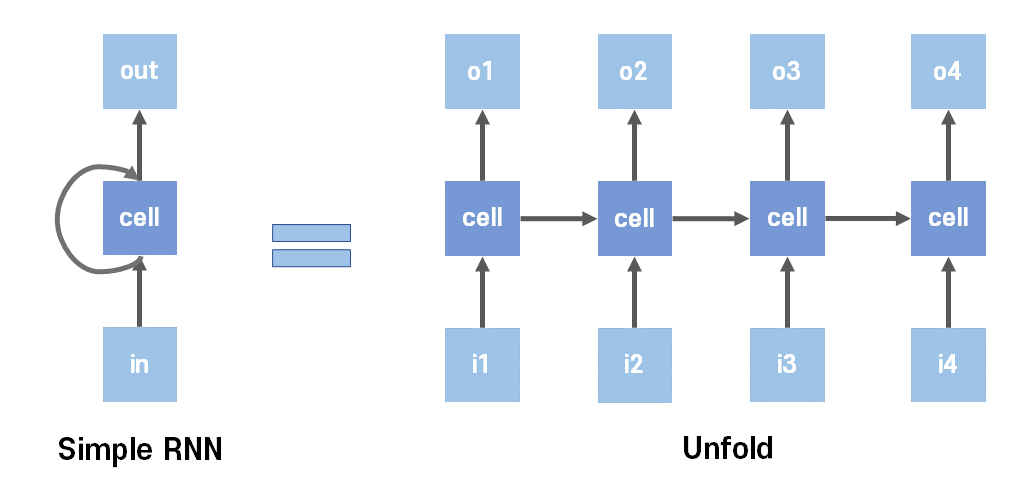
간단하게 그림으로 표현하면 위와 같은데, 이전 학습값을 기억했다가 다음 학습에 적용하는 모습이다.
이때 이 이전의 값을 저장하는 역할을 하는 은닉층을 메모리 셀, RNN 셀이라 표현하고 이 값을 은닉 상태(hiddens state)라 한다.
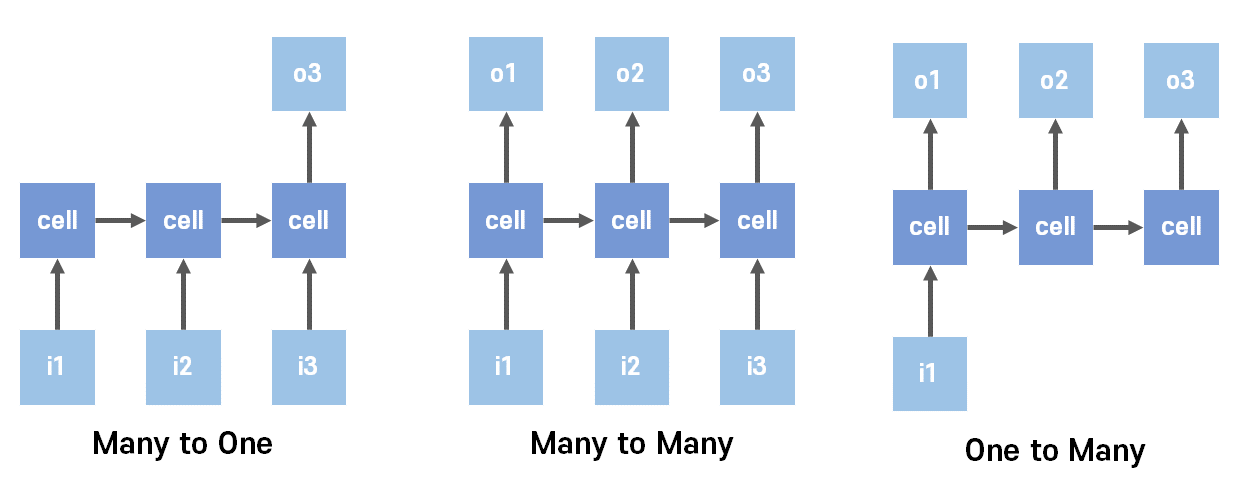
RNN은 입력과 출력의 길이를 다르게 할 수 있다는데, 이를 활용해 다양한 형태로 변형시킬 수 있다.
우선 Many to One과 같은 형태는 연속된 데이터셋인 음성으로부터 단어를 추출하는 형태로 사용된다.
One to Many는 영상이나 사진의 주석, 스팸메일 분류 등에 사용될 수 있고,
Many to Many는 챗봇, 문장 번역 등 에 사용될 수 있다.
Many to Many를 활용하여 자연어 처리에 주로 사용된 Seq-to-Seq이 등장하기도 하였는데,
Many to One을 활용한 Encoder를 통해 문장을 학습, 처리가능한 형태로 변환한 뒤 Context로 저장하고
이후 One to Many를 활용한 Decoder를 통해 우리가 원하는 결과값으로 출력하는 모델이다.
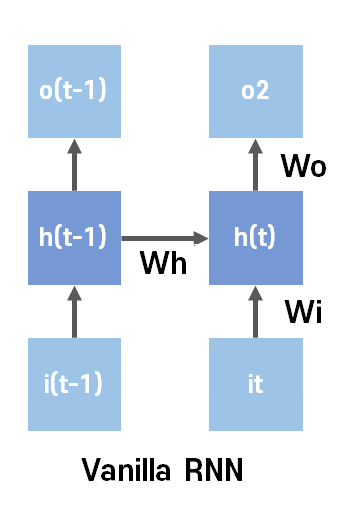
위와 같이 가장 기본인 RNN을 Vanilla RNN이라 한다. (똑같은 가중치를 사용하여 계속 계산, 학습)
LSTM (Long Short-Term Memory)
이러한 Vanilla RNN 역시 한계에 도달하게 된다. 시점이 길어질수록 앞의 은닉 상태가 점점 소실되는 것이다.
예를 들어 박찬호가 등장해서 "제가 1994년에 LA에 있었을 때...(중략)... 그래도 제가 처음 있었던 (?)에서 류현진 선수도..." 라 했을때,
맨 처음에 언급된 LA는 시간의 흐름에 따라 정보가 많이 소실되었기 때문에 추측하기 힘들게 된다.
이러한 부분을 해결하기 위해 등장한 방법이 Gate를 사용하여 이전의 내용을 얼마나 기억할 지 조절하는 방법이다.
필요한 부분이 처리되면 기억을 날려버리고, 중요한 부분은 높은 비중으로 기억하는 식의 처리를 가능하게 한다.
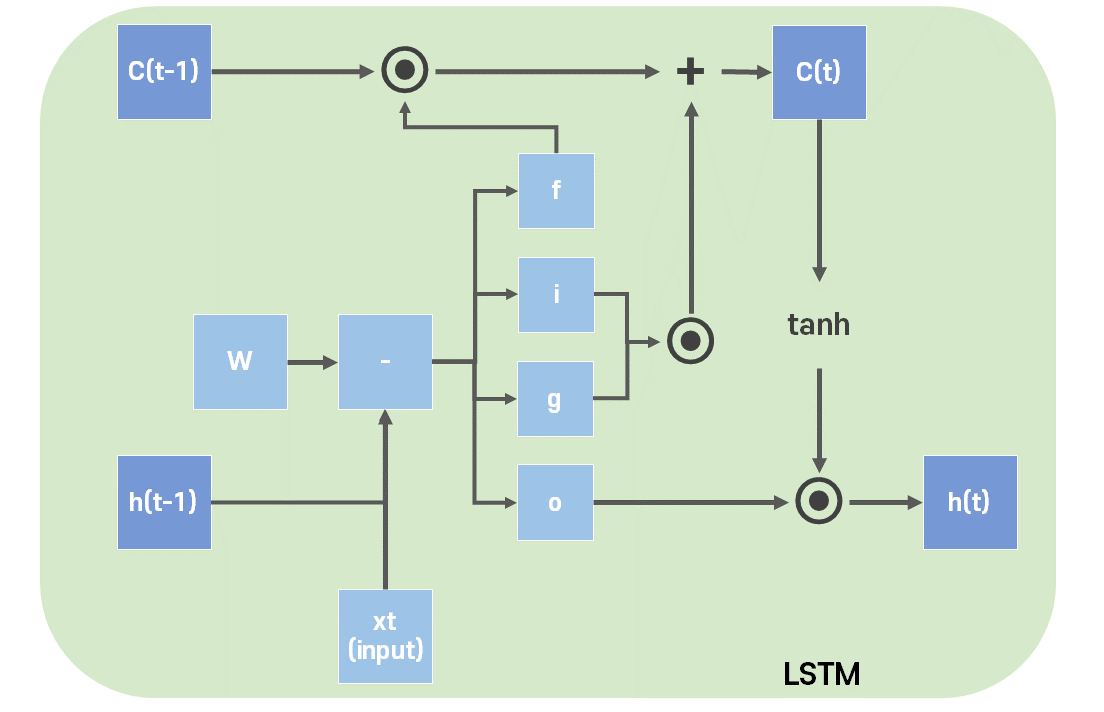
LSTM에서는 기억해야 될 요소로 은닉 상태와 함께 셀 상태를 추가하였다.
그림에서 셀 상태는 C, 은닉 상태는 h로 표현했다. 셀 상태를 장기 상태, 은닉 상태를 단기 상태라 표현하기도 한다.
또한 input, forget, output의 3가지 게이트를 사용하는데, 각각의 게이트는 다음과 같다.
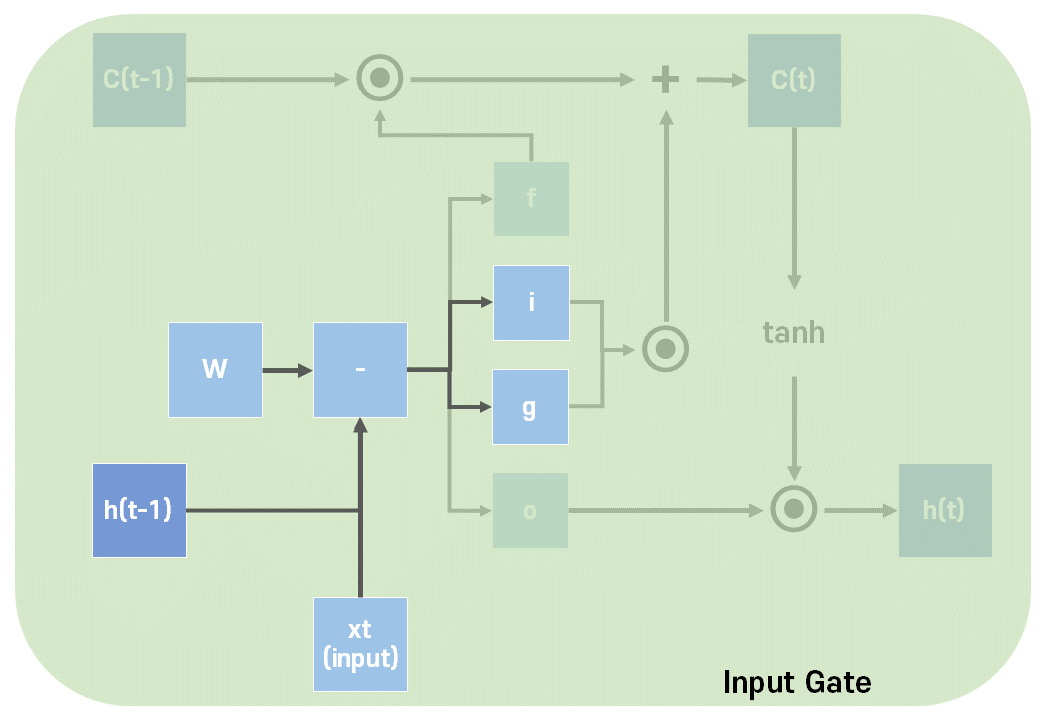
Input Gate는 현재 입력을 기억하기 위한 게이트이다.
입력과 그에 따른 가중치, 그리고 이전의 은닉 상태와 그에 따른 가중치와 bias를 합한 값을 각각 시그모이드와 하이퍼볼릭탄젠트를 지나게 하여 i(0~1), g(-1~1) 두가지 값을 만든다.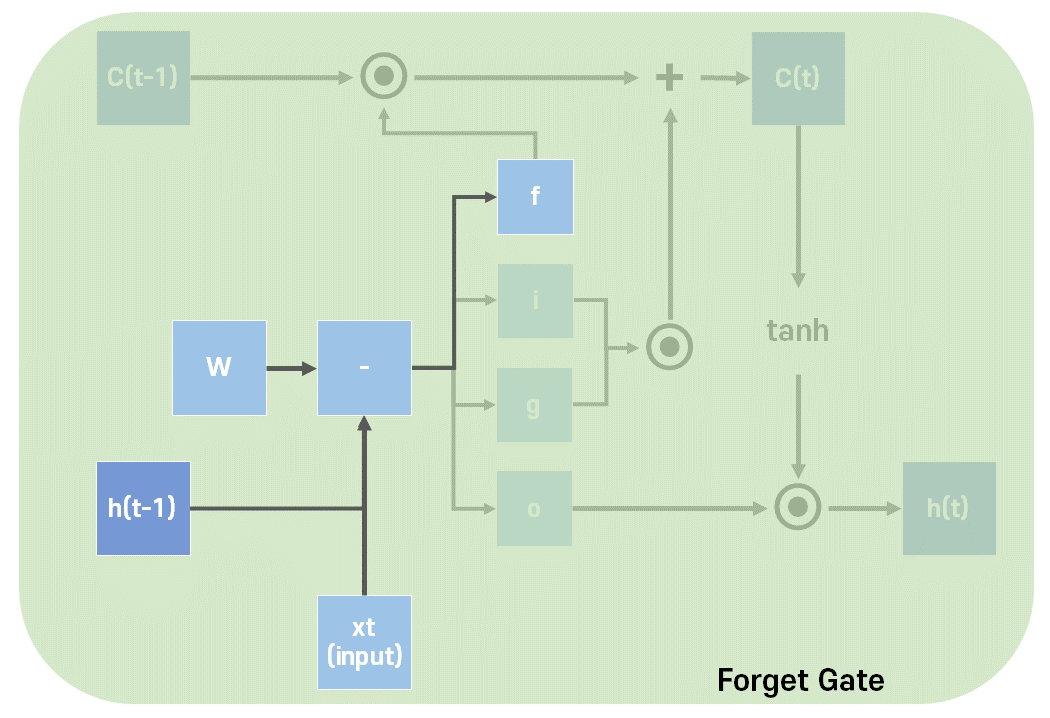
Forget Gate는 이전 상태를 얼마나 기억할지에 대한 게이트이다.
역시 입력과 그에 따른 가중치, 그리고 이전의 은닉 상태와 그에 따른 가중치와 bias를 합한 값을 시그모이드 함수를 지나게 해서 구한다.
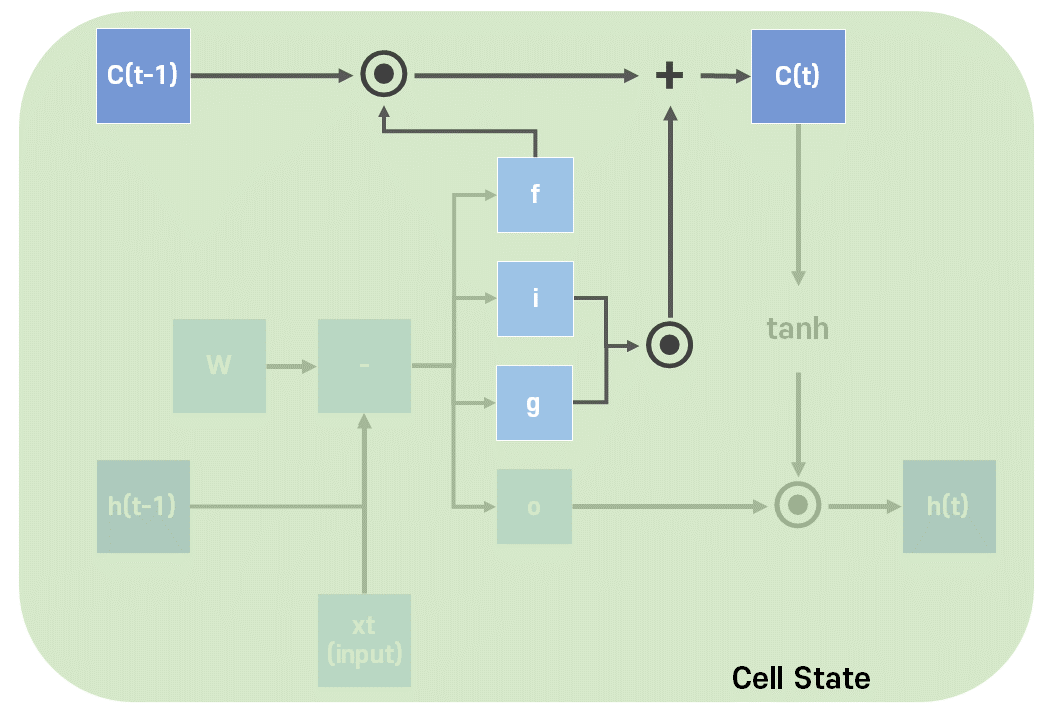
이제 이전 셀 상태와 f의 곱, i와 g의 곱의 합을 통해 현재의 셀 상태를 구할 수 있다.
만약 Forget gate의 결과가 0이면, 이전 셀 상태가 전혀 반영되지 않게 된다.
반면 Input gate에서 i, g가 0이라면 현재 셀 상태가 전혀 반영되지 않게 된다.
결과적으로 이를 통해 Input gate에서 현재 값의 반영을, Forget gate에서 이전 값의 반영을 조절할 수 있게 된다.
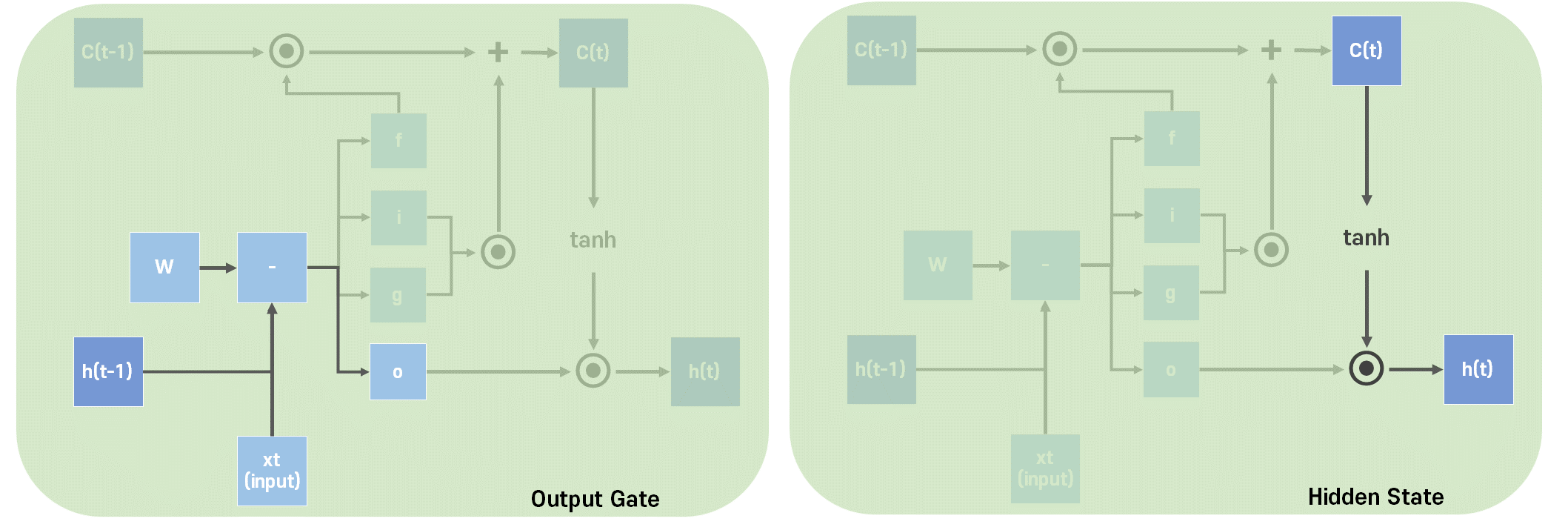
Output Gate는 얼마나 출력할지에 대한 게이트이다.
입력과 그에 따른 가중치, 그리고 이전의 은닉 상태와 그에 따른 가중치와 bias를 합한 값을 시그모이드 함수를 지나게 해서 구한다.
이제 Hidden State 이자, LSTM의 출력값을 다음과 같이 구할 수 있다.
GRU (Gated Recurrent Unit)
GRU는 LSTM이 장기적으로 기억할 수 있는 장점을 유지하면서, 기존의 3개의 게이트를 사용하던 복잡한 구조를 단순화시킨 모델이다. 셀 상태 없이 Update Gate와 Reset Gate 두 개를 사용한다.
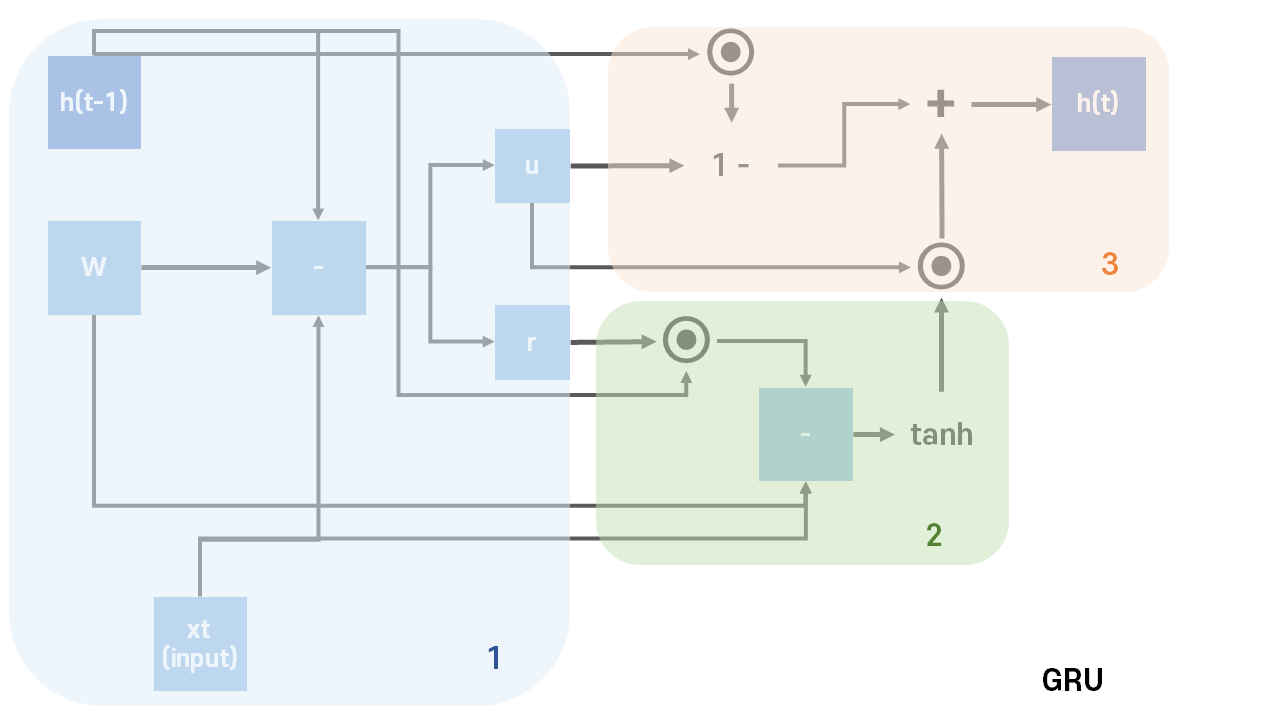
Reset Gate는 이전 값을 얼마나 기억하는지 결정해준다.
시그모이드 함수를 통해 이전 게이트를 구하는 방식과 동일하게 계산한다.
Update Gate은 이전과 현재를 어느 정도의 비율로 업데이트하는지 결정해준다.
역시 시그모이드 함수를 통해 이전 게이트를 구하는 방식과 동일하게 계산한다.
이후 그림과 같이 2번, 3번 과정을 진행하여 다음 은닉 상태이자 출력을 계산한다.
LSTM과 사실상 구조상 큰 차이가 없고, 분석 결과도 크게 차이는 없는 것으로 알려져 있다. 어쩔 때는 LSTM이 좋기도, 어쩔 때는 GRU가 좋기도 하다고 한다.
확실한 것은, GRU에서는 학습해야 할 W가 LSTM과 적은 것을 확인할 수 있다.
이후 인코더-디코더와 같은 seq2seq 구조를 유지하면서 RNN이 아닌 새로운 방식이 등장하게 되는데,
RNN의 고정 크기 벡터에 따른 정보 손실과, 기울기 소실을 보완하기 위한 Attention 메커니즘이다.
이후 2017년 구글에서 Attention을 활용한 Transformer의 발표와 함께, 이를 사용한 BERT, GPT 등의 모델들이 현재는 자연어 처리 영역에서 활발하게 사용되고 있다.
참고
딥 러닝을 이용한 자연어 처리 입문 (유원준) wikidocs.net/22886
인공지능 (유하진)