
분산학습
분산학습에는 대표적으로 모델 병렬화와 데이터 병렬화가 있습니다.
모델 병렬화는 모델의 크기가 큰 경우 여러 개의 GPU에 모델을 나누어서 적재해 학습을 하는 방법입니다. 데이터 병렬화는 여러 개의 GPU에 모델의 복사본을 적재해 다른 배치를 학습시켜 더 빠르게 학습하기 위한 방법입니다. 오늘 소개할 분산학습은 바로 데이터 병렬화입니다.
인공지능 모델은 학습하는 데에 꽤 많은 시간을 요구합니다. 이때 여러 개의 GPU를 사용한다면 훨씬 더 빠르게 학습할수 있겠죠? 파이토치는 다중 GPU를 이용한 분산학습을 용이하게 하는 모듈을 제공합니다. 바로 DistributedDataParallel입니다.
DistributedDataParallel
분산 데이터 병렬 처리는 DataParallel과 DistributedDataParallel이 있으나, 두 가지의 차이와 DistributedDataParallel을 사용하는 이유를 말씀 드리겠습니다. Data Parallel은 단일 작업, 멀티 쓰레드이며 단일 머신에서만 작동하지만, DistributedDataParallel은 다중 작업이며 단일 및 다중 기기 학습을 지원합니다. 또한 DistributedDataParallel은 모델 병렬화에서도 실행 가능합니다. 사용하기엔 DDP가 조금 더 복잡하지만 이러한 장점으로 DDP 사용을 권장합니다.
사용 방법
작업 그룹을 올바르게 설정한 후, 모델을 DDP로 감싸 줍니다.
//파이토치 예시코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
import os
import sys
import tempfile
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# 작업 그룹 초기화
dist.init_process_group("gloo", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
def demo_basic(rank, world_size):
print(f"Running basic DDP example on rank {rank}.")
setup(rank, world_size)
# 모델을 생성하고 순위 아이디가 있는 GPU로 전달
model = ToyModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(rank)
loss_fn(outputs, labels).backward()
optimizer.step()
cleanup()
def run_demo(demo_fn, world_size):
mp.spawn(demo_fn,
args=(world_size,),
nprocs=world_size,
join=True)
이점
위와 같이 DDP로 모델을 감싼 후 그 모델을 학습시키면 됩니다. 위 코드에서 world_size는 학습에 필요한 총 프로세스 수(즉 GPU 개수)이고, rank는 프로세스의 번호입니다. 이상적으로 2개의 GPU를 이용하면 싱글 GPU 대비 2배의 성능, 4개 사용 시 4배의 성능을 기대할 수 있습니다. 하지만 실제로는 그렇지 않습니다. 정비례하지 않고 이상적인 값보다 조금 못 미칩니다. 이는 모델의 크기가 클수록 심해지게 됩니다.
그 이유는 여러 가지 오버헤드 때문입니다. 첫 번째로는 DDP 모듈을 사용하는 것 자체의 오버헤드입니다. 1개의 GPU로 학습할 때, 기본 모델로 학습할 때보다 전체적인 수행시간이 느려지게 됩니다.
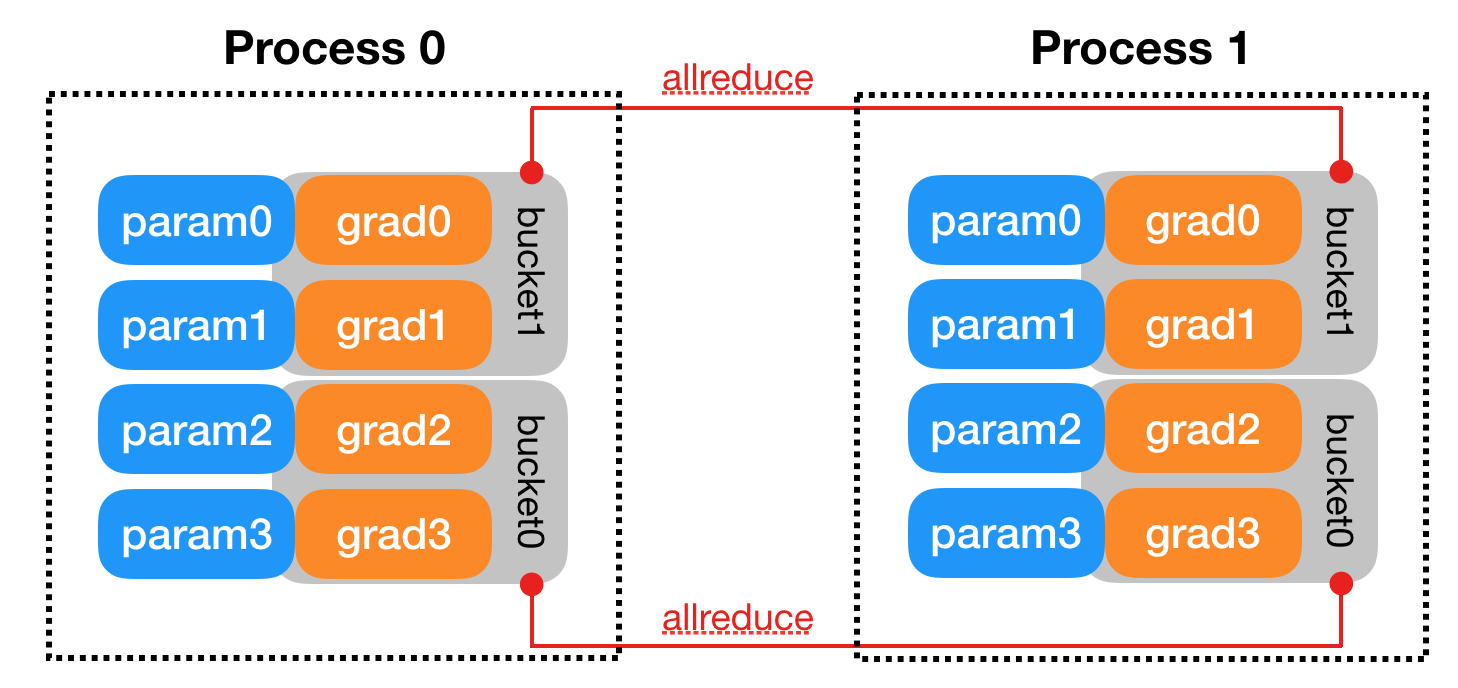
두 번째로는 GPU 간의 그래디언트 통신에 의한 통신 오버헤드입니다. DDP 수행 시 GPU 간의 통신은 역전파 연산과 겹쳐 여러 번 수행되는데, 이때 마지막에 교환되는 그래디언트는 역전파 연산이 끝난 이후에 교환되므로 역전파 연산 이후 통신 커널이 길게 나타납니다. 이는 트랜스포머와 같은 크기가 큰 모델에서 두드러지게 나타납니다.
그래디언트 통신은 역전파 이후에 드러나는 것뿐만 아니라 역전파와 겹칠 때도 미세한 속도 저하에 영향을 미칩니다. 역전파 연산 커널과 통신 커널이 동시에 수행될 때, 연산 커널만 수행되는 경우에 비해 다소 느려지는 경향이 있습니다. 이는 sgemm, cutlass와 같은 convolution 연산 커널에서 두드러지게 나타납니다.
이런 오버헤드가 있음에도 불구하고, 충분히 좋은 속도 향상을 얻을 수 있기 때문에 데이터 병렬 딥러닝을 수행하는 것은 매우 가치 있는 일입니다.
참고자료